
こんにちは。ほしのはやしです。
Rでデータを扱っていると、「NA(欠損値)」という文字に出会うことがあります。これは「そのデータが存在しない」「記録されていない」ことを意味します。統計解析やグラフ作成の前に、欠損値の扱い方を理解することはとても重要です。
この記事では、na.rmとis.na()という2つの基本的な方法を、tidyverseスタイルでやさしく解説します!
そもそもNA(欠損値)とは?
x <- c(1, 2, NA, 4, 5)このように3番目の値がNAになっている場合、「値が存在しない(欠損している)」という意味を表します。
na.rmとは?:集計関数でNAを無視する方法
例えば、mean()やsum()などの集計関数は、NAがあるとエラーになります。
x <- c(1, 2, NA, 4, 5)
mean(x)
# [1] NAこのような場合に、NAを無視して使える『na.rm = TRUE』があります!
mean(x, na.rm = TRUE)
# [1] 3これは「NAを取り除いて(remove = TRUE)、平均を計算してね」という意味です。
tidyverseでのna.rmの使い方
以下のテーブルを作成して、group毎に平均値を出したいとします。
library(tidyverse)
df <- tibble(
group = c("A", "A", "B", "B"),
value = c(1, NA, 3, 4)
)
df %>%
group_by(group) %>%
summarise(mean_value = mean(value, na.rm = TRUE))
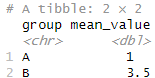
このように、mean()などの集計関数の中に、na.rm = TRUEを入れることで、除外して集計結果を出すことができます。
is.na()とは?:NAを見つける&除去する方法
is.na() は、「NAかどうか」をチェックする関数です。
先ほどのテーブルでNAがあるか確認してみましょう!
library(tidyverse)
df <- tibble(
group = c("A", "A", "B", "B"),
value = c(1, NA, 3, 4)
)
is.na(df)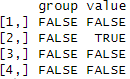
実際これを目視で確認しに行くことはなく、この仕組みでNAを同定して別の処理を行うために使っていきます。
tidyverseでNAを除去する:filter() + is.na()
先ほどのデータでNAがある行を除外していきましょう!
library(tidyverse)
df <- tibble(
group = c("A", "A", "B", "B"),
value = c(1, NA, 3, 4)
)
df %>%
filter(!is.na(value))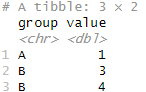
このように列を指定して、除外します!
複数の列の場合は、以下のようにします。
df <- tibble(
A = c(1, 2, NA, 4),
B = c(NA, 2, 3, 4),
C = c(5, 6, 7, NA)
)
# A, B, C のすべてに NA がない行だけ残す
df %>%
filter(if_all(c(A, B, C), ~ !is.na(.)))
NAを別の値に変更する
ときどきNAを特定の値に置き換えることもあります。
df %>%
mutate(value = if_else(is.na(value), 0, value))mutateとif_else構文をつかって、value列でNAがあるならば0、そうでないならば元の値に置き換える、という意味ですね!
全ての列のNAをチェックして、NAを含む行を除外する方法
列数が何個もあってすべて手打ちは現実的じゃない場合、すべてのNAを含む行を除外する方法もあります。
df %>%
filter(if_all(everything(), ~ !is.na(.)))everything() は「全ての列を対象にする」という意味。
~ !is.na(.) は「NAじゃない」ことをチェック。
数値列だけを対象にしたい場合はwhere(is.numeric)を使います。
df %>%
filter(if_all(where(is.numeric), ~ !is.na(.)))まとめると以下のような形です!
| 処理したい内容 | 書き方例 |
|---|---|
| 全ての列にNAがない行を残す | filter(if_all(everything(), ~ !is.na(.))) |
| 数値列にNAがない行を残す | filter(if_all(where(is.numeric), ~ !is.na(.))) |
| 全てNAの行だけ除く | filter(if_any(everything(), ~ !is.na(.))) |
 星柴くん
星柴くんNAを処理するためのコードを理解できたのだ!
 黒星柴くん
黒星柴くん大規模なデータになればなるほど使う必要があるからしっかり覚えておくんやで!
まとめ
NAをしっかり処理して集計する方法についてご説明しました!
特にtidyverseはテーブル処理で必須のパッケージですので、必ずインストールするのをおすすめします!!
皆様のお役に立てたなら幸いです。









コメント