
こんにちは。ほしのはやしです。
NA(欠損値)に対して、基本・平均値/中央値での補完の基礎について以下のページで解説してきました。


実際のデータ分析では、「グループAは平均で補完したほうがよいが、グループBは外れ値があるから中央値で補完したい」という場面があります。
本記事では、グループによって補完方法(平均 or 中央値)を切り替える方法を、tidyverseのcase_when() を使ってわかりやすく解説します!
なぜグループごとに方法を変えるのか?
例えば、グループAは値のばらつきが小さく平均が代表値になりやすいですが、グループBは外れ値を含んでいて、中央値のほうがよりロバストな代表値になる場合があります。
こうした判断は、実際のデータの分布や外れ値の有無を見ながら決めることが重要です。
サンプルデータの作成
library(tidyverse)
sales_data <- tibble(
store = c("A", "A", "A", "A", "B", "B", "B", "B"),
sales = c(100, 180, 160, NA, 200, NA, 225, 250)
)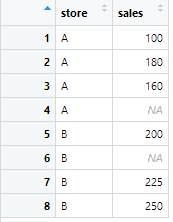
今回はこのデータを用いて、storeのグループA、グループBでそれぞれ平均値・中央値で分けて補完する方法を解説します!
実際のコード
sales_data_filled <- sales_data %>%
group_by(store) %>%
mutate(
sales_filled = case_when(
store == "A" & is.na(sales) ~ mean(sales[store == "A"], na.rm = TRUE),
store == "B" & is.na(sales) ~ median(sales[store == "B"], na.rm = TRUE),
TRUE ~ sales
)
) %>%
ungroup()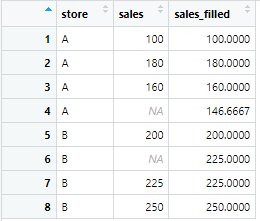
最も重要なmutateの中身についてコードを解説します!
mutate(
sales_filled = case_when(この部分で、sales_filledという列を作成し、その列にはcase_whenで計算された内容が格納されます。
store == "A" & is.na(sales) ~ mean(sales[store == "A"], na.rm = TRUE),
store == "B" & is.na(sales) ~ median(sales[store == "B"], na.rm = TRUE),
TRUE ~ salescase_when()は複数の条件を指定して、対応する条件に該当する値を割り当てます。
1行目について。
store列がAかつsales列がNAならば『store == “A” & is.na(sales)』、store列がAのsales列のすべての値『sales[store == “A”]』からNAを除いた(na.rm = TRUE)数値を平均(mean)するという意味になります!
2行目は、AがBに変わって、meanがmedianに変わっただけですね!
3行目は、1行目と2行目以外のすべての条件の場合は、sales列の元の値のままにするという意味になります。
 星柴くん
星柴くんグループに応じてNAを補完する方法を学んだのだ!
 黒星柴くん
黒星柴くんcase_whenはいろんな条件分けで使えるから慣れとくのをおすすめするやで!
まとめ
本記事では、グループによって補完方法を変えるという一歩進んだ欠損値処理の方法をご紹介しました。実際のデータ分析では、機械的に平均で埋めるのではなく、データの特徴に合わせた柔軟な対応が大切です。
特にtidyverseはテーブル処理で必須のパッケージですので、必ずインストールするのをおすすめします!!
皆様のお役に立てたなら幸いです。









コメント