
こんにちは。ほしのはやしです。
Rでデータ分析をしていると、既存のテーブル(data.frameやtibble)に新しい行を追加したい場面は多々ありますよね。
この記事では、基本のrbind()に加えて、tidyverseで使えるbind_rows()の使い方と違いをわかりやすく解説します。
目次
もともとのRにある『rbind()』で行(複数可)を追加
まずはコードをお示します。
# 1つ目のテーブル
df1 <- data.frame(name = c("Tom", "Yam"),
score = c(90, 85))
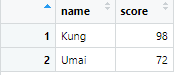
# 2つ目のテーブル(同じ列構成で)
df2 <- data.frame(name = c("Kung", "Umai"),
score = c(98, 72))
# 行を追加
df3 <- rbind(df1, df2)
View(df3)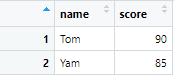
この2つを組み合わせて以下のようになります。
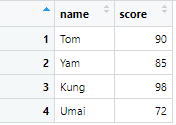
この手法では、完全に同一な列名をもったテーブルのみを結合することができます!
パッケージ(tidyverse)を用いた『bind_rows()』で行を追加
基本の操作
『bind_rows()』は、『tidyverse』パッケージに含まれるdplyrパッケージの関数で、複数のテーブルや行を柔軟に結合できます。
列名の一致だけでOKなので、『rbind()』より使い勝手が良いです。
以下がコードのサンプルになります。
install.packages(tidyverse) # 初回のみ
library(tidyverse) # パッケージの呼び出しでRを起動するたびに必要
# 1つ目のテーブル
df1 <- data.frame(name = c("Tom", "Yam"),
score = c(90, 85))
# 2つ目のテーブル(同じ列構成で)
df2 <- data.frame(name = c("Kung", "Umai"),
score = c(98, 72))
# 行を追加
df3 <- bind_rows(df1, df2)
View(df3)列の順番が違う場合
もしdf2の中身が以下のコードのように列の順番が別だったとしても、同じ列名であれば自動的に列順番を並び替えて結合してくれます!
# 2つ目のテーブル(列の順番を変えてみた)
df2 <- data.frame(score = c(98, 72), name = c("Kung", "Umai"))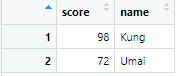
列の個数が違う場合
もし列の個数や名前が違う場合は、以下のようになります。
# 1つ目のテーブル
df1 <- data.frame(name = c("Tom", "Yam"),
score = c(90, 85))
# 2つ目のテーブル(同じ列構成で)
df2 <- data.frame(name = c("Kung", "Umai"),
score = c(98, 72), konboi = c(44, 42))
# 行を追加
df3 <- bind_rows(df1, df2)
View(df3)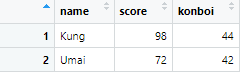
この2つが組み合わさって・・・
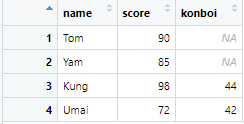
このようにデータのないところは『NA』(空白)として処理されます。
由来もとのテーブルを示す列をついでに作成する方法
どこのテーブルから来たか名前を自動でつける方法です。
# 1つ目のテーブル
df1 <- data.frame(name = c("Tom", "Yam"),
score = c(90, 85))
# 2つ目のテーブル(同じ列構成で)
df2 <- data.frame(name = c("Kung", "Umai"),
score = c(98, 72), konboi = c(44, 42))
# 行を追加
df3 <- bind_rows(list("Data1" = df1, "Data2" = df2), .id = "source")
View(df3)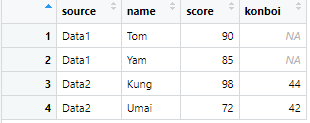
このようにdf1テーブルにはData1, df2テーブルにはData2と名付けた『source』列というのを作成しました!
まとめ
テーブルの基本操作である行の追加についてご説明しました!
特にtidyverseはテーブル処理で必須のパッケージですので、必ずインストールするのをおすすめします!!
最後にrbind()とbind_rows()の違いについて表にしました!
| 機能 | rbind() | bind_rows() |
|---|---|---|
| 異なるクラス(tibbleなど)対応 | ❌ | ✅ |
| 列順の違い許容 | ❌ | ✅ |
| 型が違っても自動補完 | ❌ | ✅(NAで補完) |
| データのラベル付け | ❌ | ✅ .id引数あり |
皆様のお役に立てたなら幸いです。









コメント