
こんにちは。ほしのはやしです。
たとえば、「スコアが90点以上の人だけ抽出したい」「性別が男性のデータだけ残したい」など、特定の条件を満たす行だけを取り出す操作は、データ分析において最もよく使われるテクニックの一つですよね。
この記事では、tidyverseのfilter()を使った特定の行の抽出方法をわかりやすく解説します!
目次
パッケージ(tidyverse)を用いた『filter()』で行を抽出
まずは以下のコードで練習用のテーブルを作成します!
library(tidyverse)
df <- tibble(name = c("Tom", "Yam", "Sue"),
score = c(90, 85, 92),
sex = c("Male", "Male", "Female"))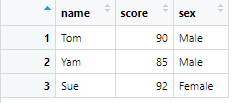
これのうち、scoreが90以上の行だけ取り出したい場合は、
# 例1: score >= 90 の行だけ取り出して、新たにdf2というテーブルを作成
df2 <- df %>% filter(score >= 90)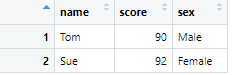
もし性別Maleだけを取り出したい場合は、以下のようにします。
# 例2: 性別Maleの行だけ取り出して、新たにdf3というテーブルを作成
df3 <- df %>% filter(sex == "Male")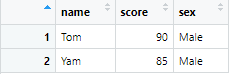
さらに発展させて、『A条件かつB条件』または『A条件またはB条件』についてのコードは以下になります。
# スコア90以上かつMaleの行を抽出
df4 <- df %>% filter(score >= 90 & sex == "Male")
# スコア90以上またはMaleの行を抽出
df4 <- df %>% filter(score >= 90 | sex == "Male") 星柴くん
星柴くんfilter以外にもsubset()があるって聞いたんだけど・・・
 黒星柴くん
黒星柴くんsubset()はRにもともと備わっているやつやね。
df4 <- subset(df, score >= 90 | sex == “Male”)
こんな感じで同じように使えるやで!
星柴くんfilterとsubsetどっち使えばいいかな?
黒星柴くん簡単なケースだと差がないけど、tidyverseパッケージを使ってパイプ演算子%>%で、どんどん条件を追加していく(行を抽出して、特定の列を削除して、など)場合は、filterを使うのがええんやで!
まとめ
テーブルの基本操作である行の抽出についてご説明しました!
特にtidyverseはテーブル処理で必須のパッケージですので、必ずインストールするのをおすすめします!!
皆様のお役に立てたなら幸いです。









コメント