
こんにちは。ほしのはやしです。
統計を考えるときに、複数の観測値をグループごとに集計することがよくあります。
たとえば、「地域ごとの売上合計」や「性別ごとの平均年齢」など。
そんなときに大活躍するのが、tidyverseのパッケージに含まれるdplyrの group_by() と summarise() です。
この記事では、初心者でも理解できるように、基本的な使い方をわかりやすく解説していきます!
目次
グループ毎での合計を求める
まずは以下のコードで練習用のテーブルを作成します!
library(tidyverse)
# 架空の売上データを作成
sales_data <- tibble(
store = c("Tokyo", "Osaka", "Tokyo", "Osaka", "Nagoya", "Tokyo"),
staff = c("A", "B", "C", "D", "E", "F"),
sales = c(100, 150, 120, 130, 90, 110)
)
sales_data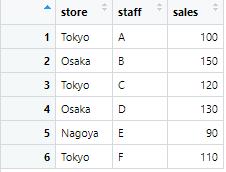
以下のコードでグループ毎に合計の値を算出します。
sales_data %>%
group_by(store) %>%
summarise(total_sales = sum(sales))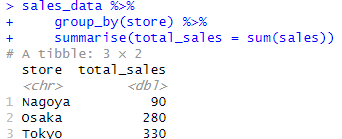
このように、『%>%』(パイプ演算子)を使うことで、データシートをグループ化(group_by)して要約する(summarise)、という表現になります。
あわせて読みたい


【初心者向け:R】欠損値(NA)を扱うには?na.rmとis.naの違いを徹底解説【tidyverse推奨】
こんにちは。ほしのはやしです。 Rでデータを扱っていると、「NA(欠損値)」という文字に出会うことがあります。これは「そのデータが存在しない」「記録されていない…
グループ毎での平均・標準偏差・95%信頼区間など求める
続いて、統計に必要な平均値などの数値をグループ毎に出す方法についてご紹介します。
library(tidyverse)
sales_data %>%
group_by(store) %>%
summarise(
count = n(), # N数の表示と、N数をcountと名付ける
total_sales = sum(sales), # 合計の表示
avg_sales = mean(sales), # 平均の表示
sd_sales = sd(sales), # 標準偏差の表示
se_sales = sd_sales / sqrt(count), # 標準誤差の表示
ci_lower = avg_sales - 1.96 * se_sales, # 95%CI下限の表示
ci_upper = avg_sales + 1.96 * se_sales # 95%CI上限の表示
)
コードを解説します。
同じように%>%をつかって、sales_dataテーブルから、store列の内容に従ってグループ分け(group_by)します。
summariseで、必要な項目を計算して表示します。
sum(), mean(), sd()の中身は計算したい数値のある列なのでsales列を入れています。
sqrt()は平方根変換のことで、count、すなわちN数を平方根変換しています。
複数列で一括に集計したい場合は下記のページをご覧ください!
あわせて読みたい

【初心者向け:R】複数の列を一括で集計するには?across()の使い方をわかりやすく解説【tidyverse推奨】
こんにちは。ほしのはやしです。 Rで複数の列に対して「平均」や「標準偏差」などを一括で計算したいとき、tidyverseパッケージに入っているacross()がとても便利です。…
 星柴くん
星柴くんグループ化とデータの要約の方法がわかったね!
 黒星柴くん
黒星柴くん要約統計をすることで外観がつかみやすくなるのええでな!
まとめ
統計の基本であるグループ化と数値の計算についてご説明しました!
特にtidyverseはテーブル処理で必須のパッケージですので、必ずインストールするのをおすすめします!!
皆様のお役に立てたなら幸いです。









コメント