
こんにちは。ほしのはやしです。
データ分析では、NA(欠損値)に遭遇するのは日常茶飯事。
そのままではエラーの原因になったり、分析に使えなかったりします。
今回は、初心者でも使いやすい「平均値補完」「中央値補完」という基本テクニックを、具体的なコード付きで解説します。
NAに関する基本的な操作は下記ページも参考にしてください!

どんなときに「平均値」「中央値」で補完するべき?
| 補完方法 | 適している状況 | 注意点 |
|---|---|---|
| 平均値で補完 | 値の分布が正規分布(左右対称)っぽいとき | 外れ値があると引っ張られる |
| 中央値で補完 | データに外れ値がある・偏っているとき | 情報が少ない場合は注意 |
基本はこのようにデータにある程度明らかな傾向がある場合に利用することができます!
方法①:平均値でNAを補完する
まずはサンプルデータを作成します。
library(tidyverse)
sales_data <- tibble(
store = c("A", "A", "A", "B", "B", "B", "C", "C", "C"),
sales = c(100, 120, NA, 200, NA, 180, NA, 300, 310)
)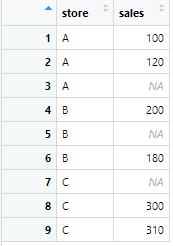
このようにsales列にNAが入っている状況を想定します。
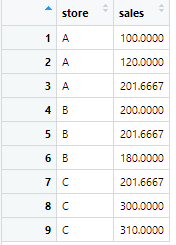
sales_data_filled <- sales_data %>%
mutate(
sales = if_else(
is.na(sales),
mean(sales, na.rm = TRUE),
sales
)
)
コードを解説します。
sales_dataというデータに対して、mutateでデータを変換します。
変換内容はmutateの括弧内で記載され、sales列の値をif_elseで条件に応じて変換するよう指示しています。
is.na(sales)は、『値がNAならば』という意味で、真ならmean(sales, na.rm = TRUE)を適応させます。偽(NAじゃない)ならもともとのsales列の値のままにしています。
mean(sales, na.rm = TRUE)は、NAを除外したsales列の平均値を出すという意味です。
方法②:中央値でNAを補完する
同様に中央値で補完する方法は以下になります。
sales_data_filled <- sales_data %>%
mutate(
sales = if_else(
is.na(sales),
median(sales, na.rm = TRUE),
sales
)
)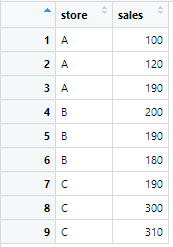
平均値の場合のmeanをmedianに変更しただけなので簡単ですね!
方法③:列ごとに平均・中央値などを分けて補完する
少し応用編です。
列の分布によっては、A列は平均値、B列は中央値として補完することもあると思います。
library(tidyverse)
sales_data <- tibble(
store = c("A", "A", "A", "B", "B", "B"),
sales = c(100, 150, NA, 200, NA, 250),
profit = c(30, NA, 45, 60, 55, NA)
)
sales_data_filled <- sales_data %>%
mutate(
sales = if_else(is.na(sales), mean(sales, na.rm = TRUE), sales),
profit = if_else(is.na(profit), median(profit, na.rm = TRUE), profit)
) 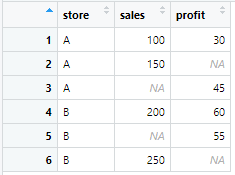
このように、mutateの中でそれぞれの列を指定して指示するだけで列毎に補完の方法を指示することができます!
 星柴くん
星柴くんNAを補完する方法を学んだのだ!
 黒星柴くん
黒星柴くんどう補完するかは議論が多いけど、分布が確からしいなら平均値・中央値補完は一つの手段として知っておいてもよいんやで!
まとめ
NAを平均値・中央値で補完する方法についてご説明しました!
特にtidyverseはテーブル処理で必須のパッケージですので、必ずインストールするのをおすすめします!!
皆様のお役に立てたなら幸いです。









コメント