
こんにちは。ほしのはやしです。
Rで複数の列に対して平均や標準偏差などを一括計算する方法として、across()+summarise()は非常に便利です。ただし、集計対象の列が増えると、出力の列数が膨大になり、非常に見づらくなってしまうのが難点です。
今回はその解決策として、pivot_longer() と pivot_wider() を使った見やすい形(tidyな形式)への変換方法をわかりやすく解説します。
acrossの使い方が基本になりますので、下記ページも参考にしてください!

複数の数値列を集計
まずは基本となるacross()による集計コードです。
library(tidyverse)
# 架空の売上データを作成
sales_data <- tibble(
store = rep(c("A", "B"), each = 5),
sales = c(100, 110, 120, 130, 140, 90, 95, 105, 115, 120),
profit = c(30, 35, 32, 34, 36, 28, 27, 29, 31, 30),
customers = c(200, 210, 220, 230, 240, 190, 195, 200, 205, 210)
)
# storeごとに集計
summary_data <- sales_data %>%
group_by(store) %>%
summarise(
across(
c(sales, profit, customers),
list(
mean = mean,
sd = sd,
se = ~sd(.) / sqrt(length(.)),
CIlow = ~mean(.) - 1.96 * sd(.) / sqrt(length(.)),
CIhigh = ~mean(.) + 1.96 * sd(.) / sqrt(length(.))
),
.names = "{.col}_{.fn}"
),
count = n()
)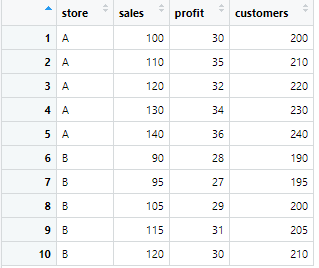

画像は結果の一部分ですが、このままだと列名がずらーっと並んで、視認性が低くなります。
解決策:pivot_longer() で「縦持ち」に整形!
この横長のデータを縦持ちに替えるには、pivot系の関数を使います!
pivot_longer() と pivot_wider() は、データの形(構造)を変えるための関数で、データの「縦持ち」と「横持ち」を切り替えるのに使います。
 星柴くん
星柴くん列が多すぎて扱いにくいから、縦に並べてスッキリさせたい時に使うんだね!
具体的には、以下のコードで縦長のデータに変換します。
summary_data_long <- summary_data %>%
pivot_longer(
cols = -c(store, count),
names_to = c("variable", "stat"),
names_sep = "_",
values_to = "value"
) %>%
pivot_wider(
names_from = stat,
values_from = value
)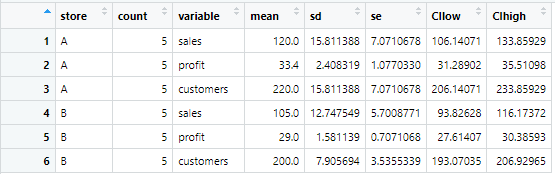
このように縦長のデータに変換できました!
まずはpivot_longer、pivot_widerにわけてコードを説明していきます!
pivot_longerの説明
前半のpivot_longerだけにすると、結果は以下になります!
summary_data_long <- summary_data %>%
pivot_longer(
cols = -c(store, count),
names_to = c("variable", "stat"),
names_sep = "_",
values_to = "value"
)変換前
変換後
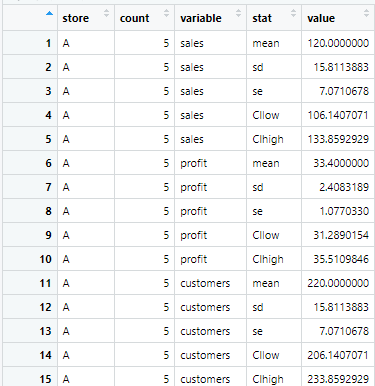
| 引数 | 内容 | 何をしてる? |
|---|---|---|
cols = -c(store, count) | 対象列の指定 | storeとcount以外のすべての列(例:sales_meanなど)を縦に変換する対象に指定。 |
names_to = c("variable", "stat") | 列名の分割先の列名 | 元の列名(例:sales_mean)を、"sales" ( variable)と"mean" (stat) に分解。 |
names_sep = "_" | 区切り文字の指定 | アンダースコア(_)で列名を分割する。例:profit_sd → "profit"と"sd"。 |
values_to = "value" | 値を格納する列名 | 各セルの数値をvalue列にまとめて入れる。 |
基本的には以下のように考えればOKです!
pivot_longer(cols = 対象にしたい列, names_to = 分割したあとの列名の決定, names_sep = “_”(対象の列をアンダーバーで区切る), values_to = 値をいれる列名)
今回はacrossで集計するときに『.names = “{.col}_{.fn}”』でアンダーバーで区切るようにしているので、その仕組みをうまく利用しています!
pivot_widerの説明
さて、pivot_longerだけだと、今度は縦に長いですよね。
これを今度は、縦に並んだ情報を、列に分けて「行数を減らす」ことを目指します。
先ほどのデータを以下のコードで横長に変換します。
pivot_wider(
names_from = stat,
values_from = value
)| 引数 | 内容 | 何をしてる? |
|---|---|---|
names_from = stat | 新しい列名のもと | stat列(mean, sdなど)の値を列名として使う。 |
values_from = value | 値のもと | value列の値(実際の数値)を、変換後の新しい列に入れる。 |
pivot_wider(names_from = 列名に変換したい情報が入っている列の名前, values_from = 新しく作る列に入れたい値が入っている列の名前)
これで最終的に以下の完成形になります!
星柴くん今回のエッセンスは、acrossで列名を作るときに『_』を使ってることだね!
 黒星柴くん
黒星柴くんハイフンでつないでる場合は、names_sep = を変更するだけで対応できるんやで!!
まとめ
acrossで一気に集計したデータを見やすい形にする方法についてご説明しました!
特にtidyverseはテーブル処理で必須のパッケージですので、必ずインストールするのをおすすめします!!
皆様のお役に立てたなら幸いです。









コメント