
こんにちは。ほしのはやしです。
いろんなデータを集めたけど煩雑だから、特定の条件を満たす列だけを取り出す操作は、データ分析において最もよく使われるテクニックの一つですよね。
この記事では、tidyverseのselect()を使った特定の列の操作方法をわかりやすく解説します!
『select()』で基本の列を抽出
まずは以下のコードで練習用のテーブルを作成します!
library(tidyverse)
df <- tibble(name = c("Tom", "Yam", "Sue"),
score = c(90, 85, 92),
sex = c("Male", "Male", "Female"))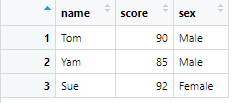
これのうち、nameとscoreの列だけ取り出したい場合は、以下のようにします。
# nameとscore列だけ取り出して、新たにdf2というテーブルを作成
df2 <- df %>% select(name, score)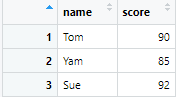
列の順番を変える
以下のコードで任意の順番に列の並びを変更することができます。
# scoreを最初に持ってくる
df3 <- df %>% select(score, everything())
# 列を任意の順番に並び替える
df4 <- df %>% select(name, sex, score)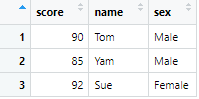
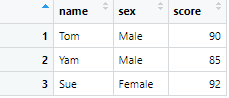
列の名前を変更する
先ほどのように、列の並び替えをするときに名前も合わせて変更することができます!
# scoreを最初に持ってきて、scoreの名前をpointに変える
df3 <- df %>% select(point = score, everything())
# 列を任意の順番に並び替えて、sexの名前をgenderに変える
df4 <- df %>% select(name, gender = sex, score)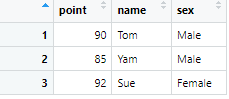
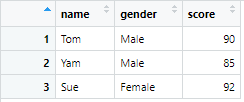
もし順番とかをいじらずに列の名前だけを変更したい場合は、renameを使って以下のようにすることもできます。
# 順番は変えずに、sexの名前をgenderに変える
df4 <- df %>% rename(gender = sex)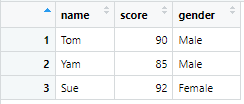
パターンで複数列を一気に抽出して選ぶ方法
以下のテーブル(data)を用いて、様々な条件での列を抽出する方法をご説明します。
data <- tibble(id = 1:3,
val1 = c(10, 20, 30),
val2 = c(5, 10, 15),
score = c(90, 85, 92))特定の文字で始まる列を抽出:starts_with()
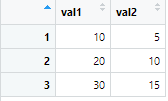
『val』から始まる列だけを抽出します。
data2 <- data %>% select(starts_with("val"))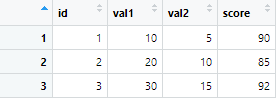
末尾が特定の文字に一致する列を抽出:ends_with()
『re』で終わる列を抽出します。
data3 <- data %>% select(ends_with("re"))特定の文字を含む列を抽出:contains()
『co』を含む列を抽出します。
data4 <- data %>% select(contains("co"))正規表現で列を抽出:matches()
これがここでは最も高度な内容で、正規表現について簡単に説明します。
正規表現とは、特殊な意味を持つ記号(メタ文字)を含むパターン文字列のことで、テキストの中から特定のパターンに合致する文字列を検索、置換、抽出するために用いられる強力なツールです。
よく使う正規表現の一例がこちらになります。
| 正規表現 | 意味 | 例(対象列名) |
|---|---|---|
^ | 先頭がこれで始まる | ^val → val1, val2 |
$ | 末尾がこれで終わる | score$ →total_score ✅ score ✅ score2025 ❌ |
. | 任意の1文字(何でも1文字) | val. → val1, val2 |
[abc] | a,b,cのどれか1文字 | ^[ST]core → Score, Tcore |
[0-9] | 数字1文字 | val[0-9] → val1, val2 |
* | 直前の文字が0回以上繰り返す | a* → “”, “a”, “aa”, … |
+ | 直前の文字が1回以上繰り返す | a+ → “a”, “aa”, … |
? | 直前の文字が0回または1回 | val[0-9]? → val, val1 |
先程の例でval1,2を抽出したい場合は、一例として以下のようにコードを書くことができます。
data5 <- data %>% select(matches("val[12]")) # val1 または val2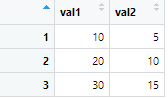
特定の列のみを除外する(-を使う)
score列を除きたいときは『-』をつけると、簡単に除外できます。
data <- tibble(id = 1:3,
val1 = c(10, 20, 30),
val2 = c(5, 10, 15),
score = c(90, 85, 92))
data6 <- data %>% select(-score) # scoreのみを除く複数の列を除きたい場合は以下のようにすることもできます。
data7 <- data %>% select(-matches("val[12]")) # val1, val2を除くテーブルを作成 星柴くん
星柴くんselect()ってめちゃくちゃ便利だね!
 黒星柴くん
黒星柴くんせやで!列操作はデータ管理の基本やからしっかり頭に叩き込むんや!
まとめ
テーブルの基本操作である列の抽出・操作についてご説明しました!
特にtidyverseはテーブル処理で必須のパッケージですので、必ずインストールするのをおすすめします!!
最後に今回お示しした、select()の使い方のまとめと例を表にしました!
| 操作内容 | 関数例 |
|---|---|
| 特定の列だけ抽出 | select(name, score) |
| 列の順番を変える | select(score, everything()) |
| 列の名前を変える | select(new_name = old_name) |
| 名前だけ変えたい | rename(new_name = old_name) |
| 部分一致で選ぶ | starts_with("val"), contains("age") |
| 特定の列を除外する | select(-score) |
皆様のお役に立てたなら幸いです。









コメント