
こんにちは、ほしのはやしです。
バイオリンプロット(violin plot)は論文でしばしば見かけますが、実際にどんな利点があるのかについてわからないこともありますよね。
このページでは、バイオリンプロットの利点と特徴、そしてRでの書き方について解説していきます!
バイオリンプロットの利点と特徴
バイオリンプロット(violin plot)が特に優れている点は、データの分布を視覚的に詳細に表現できることです。
以下の点が他のプロット(箱ひげ図やヒストグラム)と比較して優れています。
1. 分布の形状を直感的に把握できる
箱ひげ図では中央値、四分位範囲、外れ値などの要約統計を示しますが、バイオリンプロットはデータの密度分布も視覚化できるため、データの形状(多峰性や歪み)が一目でわかります。
2. 箱ひげ図の特徴も持ち合わせている
バイオリンプロットは箱ひげ図の要素(中央値や四分位範囲)を組み込むことができるため、要約統計+分布の形の両方を一つのプロットで示せます。
3. データの多峰性を視覚化できる
ヒストグラムや箱ひげ図では、データが単一のピークを持つか、複数のピークを持つかの判別が難しいですが、バイオリンプロットなら複数のピーク(多峰性)があるかどうかを視覚的に確認可能です。
4. データポイントの重なりを考慮しやすい
散布図やスウォームプロットはデータ点が重なると視認性が落ちますが、バイオリンプロットはデータの密度で表現されるため、大量のデータがあっても分布の特徴を明確に捉えることができます。
5. 異なるカテゴリ間の比較が容易
箱ひげ図でもカテゴリごとの分布比較はできますが、バイオリンプロットは密度情報を含むため、より詳細な比較が可能です。特にカテゴリごとの分布の違いを直感的に理解しやすい点が優れています。
 星柴くん
星柴くんバイオリンプロットは、箱ひげ図と密度プロットの長所を兼ね備えてるんだね!
 黒星柴くん
黒星柴くんせやで!
特にデータの分布の形状や多峰性を表現するのに優れたプロットなんや
R studioを用いたバイオリンプロットの具体例
シナリオ
ある血液検査のバイオマーカー(例:血糖値、腫瘍マーカーなど)が、健常者と病気の患者で異なる分布を持つ場合を考えます。
特定の疾患では、『患者群のデータが二峰性(低値と高値の2つの山を持つ)』になることがあります。
データシートの作成
まず、健常者(Healthy)と病気の患者(Disease)の2つのグループを作成します。
病気の患者では、二峰性のデータを持つように、2つの正規分布からデータを生成します。
# 必要なパッケージをロード
library(tidyverse)
# 再現性のためのシード設定
set.seed(123)
# ダミーデータの作成
n_healthy <- 100 # 健常者のサンプル数
n_disease <- 200 # 病気のサンプル数
# 健常者は単峰性の正規分布
healthy_values <- rnorm(n_healthy, mean = 90, sd = 10)
# 病気の患者は二峰性の分布(低値と高値の2つの山を持つ)
disease_values_low <- rnorm(n_disease / 2, mean = 70, sd = 8)
disease_values_high <- rnorm(n_disease / 2, mean = 130, sd = 10)
disease_values <- c(disease_values_low, disease_values_high)
# データフレームにまとめる(Groupの順序を Healthy → Disease に固定)
df <- data.frame(
Group = factor(rep(c("Healthy", "Disease"), c(n_healthy, n_disease)),
levels = c("Healthy", "Disease")),
Biomarker = c(healthy_values, disease_values)
)
# データの確認
summary(df)このデータシート『df』を用いて、バイオリンプロットと箱ひげ図を重ねて書いて二縫性かどうか確認していきます。
# バイオリンプロットの作成
ggplot(df, aes(x = Group, y = Biomarker, fill = Group)) +
geom_violin(trim = FALSE, alpha = 0.6) + # バイオリンプロット
geom_boxplot(width = 0.1, outlier.shape = 19) + # 箱ひげ図を重ねる(外れ値なし)
theme_classic() + # クラシックなテーマ
labs(title = "Biomarker Distribution in Healthy and Disease Groups",
x = "Group", y = "Biomarker Level") +
scale_fill_manual(values = c("Healthy" = "gray", "Disease" = "blue")) # 色の設定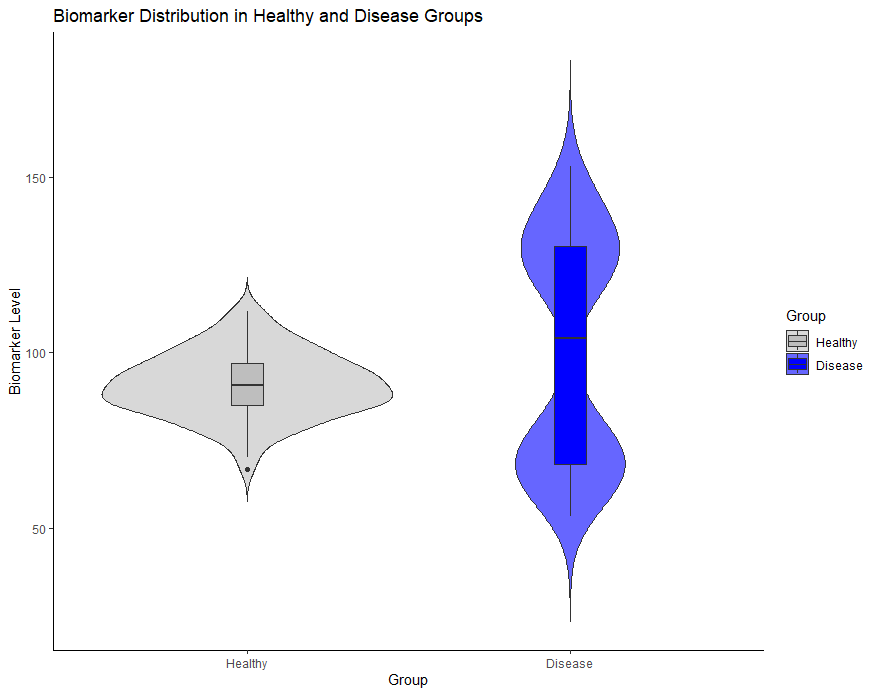
このように箱ひげ図だけだと、二峰性かどうか全くわかりませんが、バイオリンプロットを重ねることで二峰性の分布がありそうということがわかります!
二峰性かどうかの確認
データが二峰性かどうかを確認するために、密度プロットやヒストグラムを用いた解析を行います。
# ヒストグラムと密度プロットをグループ別に表示
ggplot(df, aes(x = Biomarker, fill = Group)) +
geom_histogram(aes(y = ..density..), bins = 30, alpha = 0.5, position = "identity") +
geom_density(alpha = 0.6) +
facet_wrap(~Group, scales = "free") + # グループ別に分割
theme_classic() +
labs(title = "Histogram and Density of Biomarker Levels",
x = "Biomarker Level", y = "Density") +
scale_fill_manual(values = c("Healthy" = "gray", "Disease" = "blue"))
このようにグループ毎にヒストグラムと密度分布を作成することでより二峰性らしさがわかりやすくなりました!
二峰性の統計的検定
二峰性かどうかを確認するために、Hartigan’s Dip Test(dip.test)を用います。
これは、簡単に説明すると、二峰の間の谷の深さを比較する検定です。
# dip.testのためのパッケージ
install.packages("diptest") # 初回のみ
library(diptest)
# 健常者と病気の患者のデータをテスト
dip_healthy <- dip.test(df$Biomarker[df$Group == "Healthy"])
dip_disease <- dip.test(df$Biomarker[df$Group == "Disease"])
# 結果の表示
print(dip_healthy)
print(dip_disease)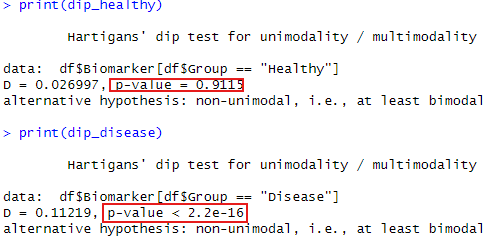
本ページでは扱いませんが、他の二峰性の検定の特徴と限界をまとめました。
| 検定 | 特徴 | 利点 | 限界 |
|---|---|---|---|
| Hartigan’s Dip Test | CDFの最大乖離を測定 | 一般的に使われる | 二峰性の形に影響を受けやすい |
| Silverman’s Test | KDEのピーク数を検定 | 柔軟な適用が可能 | バンド幅に依存 |
| Ashman’s D | 平均の差で二峰性を定量化 | 数値的に評価可能 | 2つの正規分布の混合を仮定 |
| Excess Kurtosis | 分布の尖度を評価 | 簡単に計算可能 | 単純すぎる |
※KDE:データ分布の平滑化されたヒストグラム(カーネル密度推定)
二峰性がある場合に考えること
二峰性がある場合は、データの扱い方に慎重な対応が必要です。
1. データの再確認と検証
まずは、測定手法が間違ってないか、データの入力ミスがないかの確認が必要です。
可能であれば、サンプルのランダムピックアップ再解析などで、データが大きく異なることでないことを再確認する必要があります。
2. 集団の異質性の検討
臨床データの場合、異なる性質を持つ複数の集団(例えば、性別、年齢、遺伝子型など)の混合である可能性があります。
この場合は、集団を分割して分析することで、各集団の分布を明らかにすることが有用です。
実験系の場合は、個体の状況や環境要因が影響を与えている可能性があるため、考察が必要です。
星柴くん二峰性がある場合は、間違いないか確認した上で、再度グループ分けをすることを考えればいいんだね!
黒星柴くんヘテロな原因を考えて突き詰めることで新たな発見が見つかることがあるから、テンション上がるでな!
まとめ
バイオリンプロットの概略・利点、そして二峰性の統計手法などについて解説しました!
皆様のお役に立てたなら幸いです。









コメント