
こんにちは。ほしのはやしです。
欠損値は、統計解析や機械学習でしばしば避けられない問題です。
特に、感度分析を行う際に欠損値があると、結果の信頼性に大きく影響を及ぼします。
このページでは、Rのmiceパッケージを使って欠損値を補完(インプテーション)し、その後に感度分析を行う方法を紹介します。
また、「欠損があるデータでどのくらい結果が変わるのか?」という感度分析の観点から、miceをどう活用すべきかも解説します。
欠損値についての基本的な知識については以下のページを参考にしてください!

感度分析とは?
感度分析(Sensitivity Analysis)とは、入力の不確実性(たとえば欠損値の補完方法など)によって、解析結果がどの程度変わるかを評価する手法です。
特に欠損データが多い場合、
- 単純な除外(complete-case analysis)ではバイアスが生じる可能性がある
- どの補完法を選ぶかで推定結果が変わる
こうした不確実性を評価するために、「補完後の複数のデータセットを使って感度分析を行う」ことが重要です。
感度分析についての基本的な知識は以下のページを参考にしてください!

miceパッケージとは?
mice(Multivariate Imputation by Chained Equations)は、多重代入法を用いて欠損データを補完する強力なRパッケージです。
以下のような特徴があります:
- 補完した複数のデータセットをまとめて解析できる
- 多変量補完に対応
- 補完方法(線形回帰、ロジスティック回帰など)を指定可能
特にプログラミングコードも少なくできるため、NAの処理や感度分析をする際には非常に重要なパッケージになります!
パッケージのインストール方法は以下のページを参考にしてください!

基本的なmiceの使い方(R studio)
パッケージはmiceとtidyverseを利用します。
miceパッケージに付属しているデータセット『nhanes』を用いて、以下の例をお示しします。
# パッケージの読み込み
library(mice)
library(tidyverse)
# 欠損を含むデータ例
data("nhanes", package = "mice")
View(nhanes)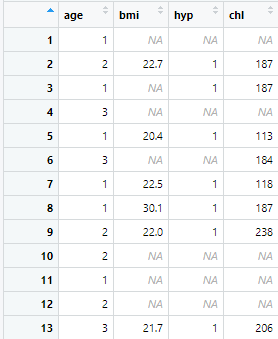
このようにage, bmi, hyp(高血圧), chl(コレステロール)の架空のデータセットを展開しました。
続いてこの『NA』(欠損値)を多重代入法を用いて、練習用に特に考えずに補完します。
# 多重代入を実行(m = 5 回補完)
imp <- mice(nhanes, m = 5, method = 'pmm', seed = 123)
# 補完されたデータの1つを確認
completed_data1 <- complete(imp, 1)
View(completed_data1)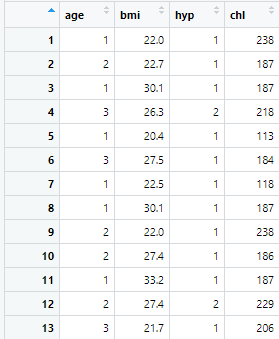
補完を5回、すなわち5個のデータができることになります。
そのうちの1つを確認したのが上の画像になります。
 星柴くん
星柴くんなんかageとhypの数値変だけど一律で補完していいのかな?
 黒星柴くん
黒星柴くんええとこに気づいたな!
あとで解説するけど、データの種類に応じて本当は補完方法変えなあかんねんで!!
星柴くん記事を最後まで読む事が大事なんだね!!!
コードの解説
このコードは、nhanesというデータセットに含まれる欠損値を、5回の多重代入(multiple imputation)によって補完する処理になります。
| 引数 | 説明 |
|---|---|
| nhanes | 補完対象となるデータ。miceパッケージに付属する例のデータセットで、いくつかの変数に欠損があります。 |
| m = 5 | 5回補完する、つまり5個の異なる補完済みデータセットを作るという意味です。多重代入では1回だけの補完だと不十分なため、複数回行います。 |
| method = ‘pmm’ | 『Predictive Mean Matching(予測平均マッチング)』という補完方法を指定しています。これは、連続変数に対して使われる一般的で信頼性の高い方法です。 |
| seed = 123 | 結果の再現性を保つための乱数の種です。これを設定することで、毎回同じ結果を得られるようにしています。 |
なぜ複数回補完するの?
データに含まれる「欠損の不確かさ」を考慮するため。
1回だけ補完しても「たまたまそうなっただけ」かもしれないので、『複数回補完して結果を統合(pool)』するのが基本です。
PMMってなに?
「似たような値」を持つ観測から実際の値をコピーしてくる方法。
つまり、実際にありそうな値を使うので非現実的な値が出にくいという利点があります。
miceによる複数の補完データを統合して頑健な結果を作成
多重代入で生成された複数の補完データセットに対して、同じ解析(たとえば回帰分析:bmiをageとhypで説明する)を実行し、その結果を統合します。
# 例:線形回帰モデルを各補完データに適用
fit <- with(imp, lm(bmi ~ age + hyp))
# 各データの結果をプール(統合)して推定
summary(pool(fit))
欠損値があると、1回だけ補完したデータに基づいた解析結果は、たまたま得られた結果で、真の傾向からズレる可能性があります。
そこで、『複数回補完して複数の解析結果を得てから、それらを統合(Rubinのルールに基づいて集約)』することで、欠損による不確かさを反映した、より信頼できる結論を得ることができます。
補完された結果毎でばらつきが激しくないか可視化
今回は5個の補完データを作成しましたが、これら自体が大きくばらつきがないか可視化することも重要です。
# 補完後のデータごとに回帰係数を抽出し、変動を確認
results <- lapply(1:5, function(i) {
data_i <- complete(imp, i)
model <- lm(bmi ~ age + hyp, data = data_i)
coef(model)
})
results_df <- do.call(rbind, results)
boxplot(results_df)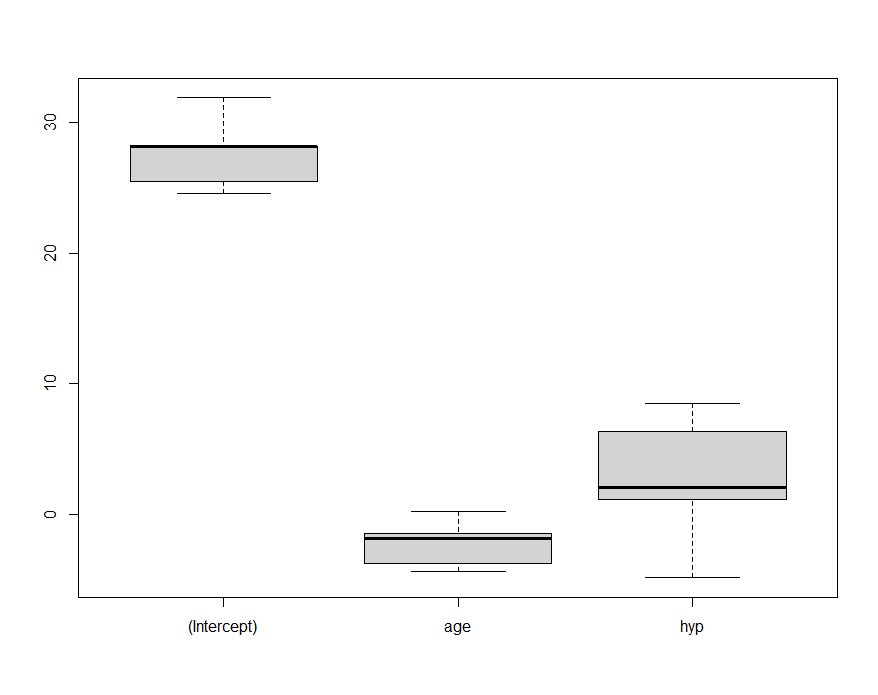
このようにみると、hypのばらつきが大きいことがわかります。
元のデータの説明サイトを確認(https://rdrr.io/cran/mice/man/nhanes.html)するとageおよびhypは具体的な年齢や血圧の値ではなく、age=年齢別グループ、hyp=高血圧の有無(1=No, 2=Yes)、だったことがわかりました。

補完方法をまず適切にする必要があります。
列の種類によってmiceによる補完方法を変える方法
まずは、ageとhypを連続変数からカテゴリー変数に、またhypについては、1から0, 2から1に変更して、解析できるようにデータセットを調整します。
library(mice)
data(nhanes)
# ageをカテゴリー別に変更して、連続変数からカテゴリー変数に変換する(ラベルもつける)
# age: 1 = 20–39, 2 = 40–59, 3 = 60+
nhanes$age <- factor(nhanes$age,
levels = c(1,2,3),
labels = c("20–39", "40–59", "60+"))
# hypを1を0, 2を1にして、2カテゴリの解析をできるようにする
nhanes$hyp <- ifelse(nhanes$hyp == 1, 0,
ifelse(nhanes$hyp == 2, 1, NA)) # NAのまま保持
# hypを連続変数からカテゴリー変数に変換する(わかりやすいようにラベルもつける)
nhanes$hyp <- factor(nhanes$hyp, levels = c(0,1), labels = c("No", "Yes"))
ここで以下の基本知識に基づいて、列ごとに補完方法を変えていきます。
- age はカテゴリ変数として解釈されるため、polyreg(多項ロジスティック回帰)で補完するのが自然。
- hyp はYes/Noの2カテゴリなので、logreg(ロジスティック回帰)が適切。
- bmi, chl は数値データなので、pmm(predictive mean matching)での補完がよく使われます。
# 変数に合った補完手法を指定:
# bmi & chl: "pmm"(連続値の推定平均マッチング)
# hyp: "logreg"(2値ロジスティック回帰)
# age: "polyreg"(3カテゴリの補完)
imp <- mice(nhanes, method = c(age = "polyreg", bmi = "pmm", hyp = "logreg", chl = "pmm"),
m = 5, seed = 123)これで正しい補完データセットができたので、前回と同様に解析しましょう。
# 例:線形回帰モデルを各補完データに適用
fit <- with(imp, lm(bmi ~ age + hyp))
# 各データの結果をプール(統合)して推定
summary(pool(fit))
さらに可視化も行います。
# 補完後のデータごとに回帰係数を抽出し、変動を確認
results <- lapply(1:5, function(i) {
data_i <- complete(imp, i)
model <- lm(bmi ~ age + hyp, data = data_i)
coef(model)
})
results_df <- do.call(rbind, results)
boxplot(results_df)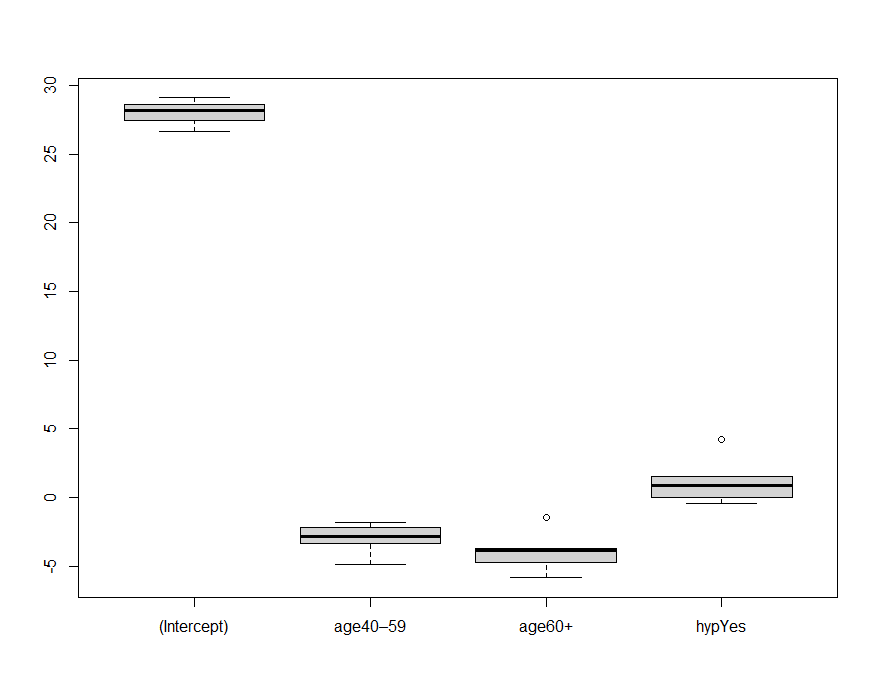
ばらつきが小さく、補完方法によっても大きな差がないということがわかりました!
星柴くんもしこれでもバラツキが多い場合はどうするの?
黒星柴くんその場合は、補完回数を5から20, 50など増やすんや!
補完回数を増やすことで、推定値の安定性が高まるからおすすめやで!
星柴くん実際にはどのくらいにすればいいのかな?
黒星柴くん脳死でm=20でとりあえずOKやで!
ボスによってこだわりがあるから、その場合は絶対服従するのが処世術やでな!
感度分析として検討すべきポイント
欠損値があるデータに対して、miceパッケージで補完を行い解析した後、補完の方法(例:pmm・norm・logregなど)を変更しても、同様の結果が得られるかどうかを確認します。
これを結論の頑健性(robustness)を検証する感度分析といいます。
| 感度分析の方法 | 例 |
|---|---|
| 補完手法の変更 | method = “pmm” → “norm” に変えて再解析 |
| 補完回数の変更 | m = 5 → m = 20 にしてみる |
| 欠損値を含まない完全ケースで解析 | na.omite(データシート名)で除外して再度解析 |
| 故意にバイアスを入れて補完 | 最悪シナリオやベストシナリオで補完する(医学研究でよく使う) |
まとめ
本記事では、miceを用いた欠損値の対応と感度分析における使い方について説明しました!
- 感度分析では、「欠損値の扱い方によって結果が変わるか?」をチェックすることが重要
- miceを使えば、欠損データに対する複数の補完を実行し、感度分析を行うためのベースが整う
- 単に1回だけ補完して終わりにするのではなく、複数補完結果の比較・統合・可視化が、感度分析として大切
皆様のお役に立てたなら幸いです。








コメント