
こんにちは。ほしのはやしです。
フォレストプロットはビジュアルでわかりやすく大人気ですが、いまいち書き方について説明したサイトないことに今更ながらに気づきました。
特に臨床研究などで見られるサブグループ解析でのフォレストプロットをRで書くには、ひと工夫必要ですので具体的な方法について説明していきます!
 星柴くん
星柴くんメタアナリシスのページばっかり出て調べるのが大変だったのだ!
 黒星柴くん
黒星柴くんメタアナリシスするような教室やとSPSSとか持ってるからニーズなかったりするんやで
フォレストプロットとは?
元々フォレストプロットは、複数の研究結果を視覚的に比較するためのグラフです。
特に、メタアナリシス(メタ分析)と呼ばれる、複数の研究結果を統合して解析する際に頻繁に使われます。
昨今では、サブグループ解析・感度分析にも用いられるため、フォレストプロットの書き方を学ぶことは重要です。
しかしながら、データテーブルから一気にフォレストプロットを出力するパッケージはRにはなく、多くの研究者はSPSSなど超高額な有料ソフトを使っている現状があり、フリーソフトのRでフォレストプロットを書くことは資金を節約する上でも大切です。
サブグループ解析とは?
サブグループ解析とは、臨床試験の結果を、特定の特性を持つグループ(サブグループ)ごとに分けて解析することです。
例えば、年齢、性別、疾患の重症度など、患者に特徴的な要素を基にグループ分けし、それぞれのグループにおいて治療効果が異なるかどうかを調べます。
フォレストプロットを用いることで、全体の傾向と違う因子を視覚的に表すことができるのが大きなメリットです。
R studioでのフォレストプロットの具体的な書き方
練習用データの作成
やりたいこと:新薬vsプラセボで心筋梗塞発生率に差があるかという研究で、サブグループ解析をしたい
#練習用データ
PatientID: 患者の識別子
Age: 年齢(連続変数)
Sex: 性別(”Male” または “Female”)
Hypertension: 高血圧の有無(1: あり, 0: なし)
Diabetes: 糖尿病の有無(1: あり, 0: なし)
Group: 割り付け群(”NewDrug” または “Placebo”)
Time: フォローアップ期間(週数)
Event: 心筋梗塞の発生有無(1: 発生, 0: 発生なし)
# 練習用データの作成
set.seed(123) # 再現性のためのシード
n <- 200 # 患者数
# 各変数を生成
PatientID <- 1:n
Age <- round(runif(n, 50, 80)) # 年齢: 50歳から80歳
Sex <- sample(c("Male", "Female"), n, replace = TRUE)
Hypertension <- sample(c(0, 1), n, replace = TRUE, prob = c(0.6, 0.4))
Diabetes <- sample(c(0, 1), n, replace = TRUE, prob = c(0.7, 0.3))
Group <- sample(c("NewDrug", "Placebo"), n, replace = TRUE)
Time <- round(runif(n, 1, 52)) # フォローアップ期間(週)
Event <- rbinom(n, 1, ifelse(Group == "NewDrug", 0.15, 0.25)) # イベント発生率の差を反映
# データフレームを作成
datasheet1 <- data.frame(PatientID, Age, Sex, Hypertension, Diabetes, Group, Time, Event)このスクリプトで以下のような表を作成しました!
テーブル名:datasheet1
| PatientID | Age | Sex | Hypertension | Diabetes | Group | Time | Event |
|---|---|---|---|---|---|---|---|
| 1 | 59 | Female | 1 | 0 | NewDrug | 15 | 1 |
| 2 | 74 | Female | 0 | 0 | NewDrug | 31 | 1 |
| 3 | 62 | Female | 1 | 0 | Placebo | 9 | 0 |
| 4 | 76 | Male | 0 | 0 | Placebo | 45 | 0 |
| 5 | 78 | Female | 0 | 0 | NewDrug | 44 | 0 |
| 6 | 51 | Female | 0 | 1 | NewDrug | 25 | 1 |
| 7 | 66 | Male | 1 | 0 | NewDrug | 40 | 1 |
| … | … | … | … | … | … | … | … |
多くの場合、このような形でエクセルなどにデータを集積していると思います。
サブグループ解析してフォレストプロットで図示するためには連続変数をカテゴリー変数(群分け)することが必要ですので、年齢を65歳未満・65歳以上の2群に分けます。
#AgeGroup列を追加
datasheet1$AgeGroup <- ifelse(datasheet1$Age < 65, "<65", ">=65")全体およびサブグループでのハザード比の計算
作業量を減らすために関数を作成していきますが、ここが難しく感じるかもしれません。
汎用関数の作成
全体およびサブグループで生存分析をまとめて行うために関数を作成します。
※この部分はデータシート名や列名が異なっていてもこのまま貼り付けでOKです!
library(tidyverse)
library(survival)
perform_analysis <- function(data, group_var = NULL) {
if (!is.null(group_var)) {
# サブグループ解析
results <- by(data, data[[group_var]], function(subgroup_data) {
analyze_cox_model(subgroup_data, subgroup_data[[group_var]][1])
})
do.call(rbind, results)
} else {
# 全患者解析
analyze_cox_model(data, "All patients")
}
}これにより以下の関数が完成しました!
perform_analysis(データシート名, サブグループ解析したい列名)
Coxモデル解析と結果をまとめる関数作成
Cox比例ハザードモデルで解析する関数を作成します
analyze_cox_model <- function(data, subgroup_name) {
# サバイバルオブジェクトを作成(ここのTime, Eventは自分のデータの列名に応じて変更してください)
surv_obj <- Surv(time = data$Time, event = data$Event)
# Cox比例ハザードモデルを適用(ここのGroupは自分のデータの列名に応じて変更してください)
cox_model <- coxph(surv_obj ~ Group, data = data)
# HR, 95%CI, p値を取得
hr <- exp(coef(cox_model))
ci <- exp(confint(cox_model))
pval <- summary(cox_model)$coefficients[5]
# 各群のN数を計算(ここのGroup, "NewDrug", "Placebo"は自分のデータの列名や内容に応じて変更してください)
counts <- table(data$Group)
new_drug_count <- counts["NewDrug"]
placebo_count <- counts["Placebo"]
# 結果をデータフレームとして返す
data.frame(
Subgroup = subgroup_name,
NewDrug = ifelse(is.na(new_drug_count), 0, new_drug_count),
Placebo = ifelse(is.na(placebo_count), 0, placebo_count),
HR = hr,
CI_Lower = ci[1],
CI_Upper = ci[2],
p_value = pval
)
}サブグループ解析の実行
調べたいサブグループ(今回の場合は、年齢、性別、高血圧、糖尿病)に対して解析を行います。
# list()の中身は自分の調べたいサブグループの列名に応じて変更してください
subgroups <- list(
AgeGroup = "AgeGroup",
Sex = "Sex",
Hypertension = "Hypertension",
Diabetes = "Diabetes"
)
# datasheet1はデータシート名に応じて変更してください
subgroup_results <- lapply(names(subgroups), function(var) {
cbind(Variable = var, perform_analysis(datasheet1, subgroups[[var]]))
})全体解析の実行
続いて全患者に対する解析を行います。
all_patients_result <- cbind(Variable = "All patients", perform_analysis(datasheet1))結果の統合
全体解析結果とサブグループ解析結果を統合します。
all_results <- do.call(rbind, c(list(all_patients_result), subgroup_results))view(all_results)で以下のような表でまとまったことがわかります!
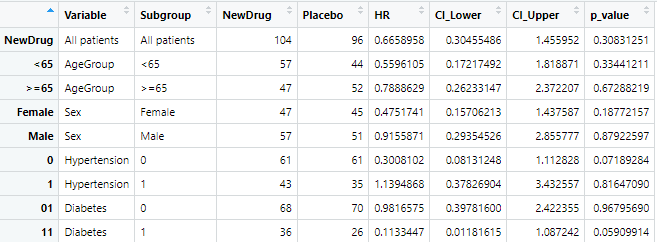
フォレストプロット作成用にデータを変形
フォレストプロットを美しく見えるようにデータを変形します。
# 空白行を作成(適宜列名に応じて以下の内容は変更してください)
empty_rows <- data.frame(
Variable = NA, Subgroup = NA, NewDrug = NA, Placebo = NA,
HR = NA, CI_Lower = NA, CI_Upper = NA, p_value = NA,
stringsAsFactors = FALSE
)
# 空白行を4つ複製(今回4因子でサブグループ解析したので4つ複製します)
empty_rows <- empty_rows[rep(1, 4), ]
# Subgroup列にリストの値を挿入(このsubgroupは【サブグループ解析の実行】で作成したリストに対応しています)
empty_rows$Subgroup <- unlist(subgroups)
# all_results に新しい行を追加
all_results <- rbind(all_results, empty_rows)
# 指定した行番号順(行をマニュアルで指定して並び替えます)
row_order <- c(1, 10, 2, 3, 11, 4, 5, 12, 6, 7, 13, 8, 9)
# 並び替え
all_results <- all_results[row_order, ]
# 最初の列と最後の列を同時に削除
all_results <- all_results[, -c(1, ncol(all_results))]
# 新しい列 se(ハザード比の標準誤差) を作成
all_results$se <- (log(all_results$CI_Upper) - log(all_results$HR)) / 1.96
# 結果を確認
view(all_results)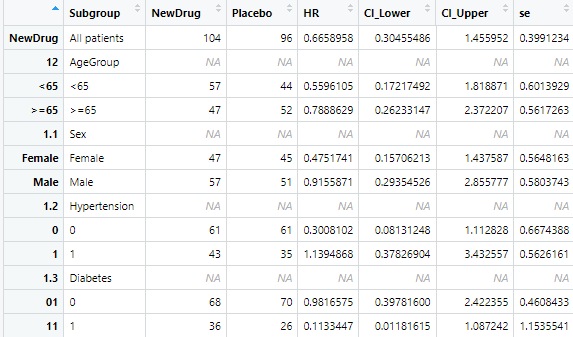
フォレストプロットの棒線を描画するために空白行を、HR(95% CI)を表す行を作成します。
またSubgroupの名前やインデントを調整します。
# 空白行を20個作成。もしフォレストプロットの横線が足りなければ30,40などに増やす
all_results$` ` <- paste(rep(" ", 20), collapse = " ")
# 描画用のHR(95% CI)を作成する
all_results$`HR (95% CI)` <- ifelse(is.na(all_results$se), "",
sprintf("%.2f (%.2f to %.2f)",
all_results$HR, all_results$CI_Lower, all_results$CI_Upper))
# Subgroup列の名前を変更する(0, 1をNo, Yesに変更する)
all_results$Subgroup <- ifelse(all_results$Subgroup == 0, "No",
ifelse(all_results$Subgroup == 1, "Yes", all_results$Subgroup))
# 見やすい用にSubgroupのインデント調整(Placeboに数値があればインデント" "を入れるようにする)
all_results$Subgroup <- ifelse(is.na(all_results$Placebo),
all_results$Subgroup,
paste0(" ", all_results$Subgroup))
# NAが表示されないように消す(NewDrug, Placeboの列にあるNAを空白にする)
all_results[c("NewDrug", "Placebo")] <- lapply(all_results[c("NewDrug", "Placebo")], function(x) {
x[is.na(x)] <- ""
x
})
# 結果を確認
view(all_results)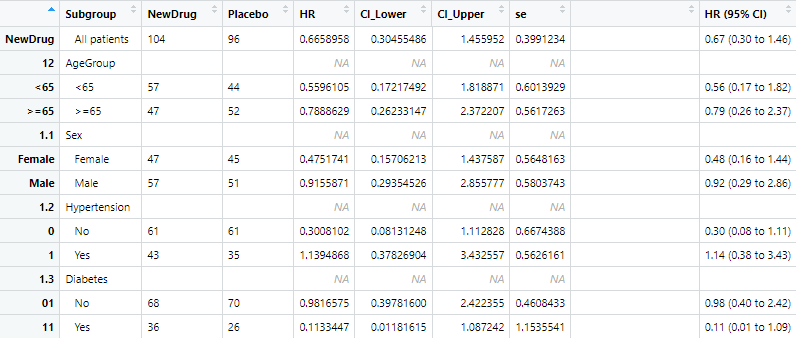
Forestploterでサブグループ解析のグラフ作成
パッケージ Forestploterをインストールしてください。
一般的なパッケージのインストール方法はこちら!

以下がコードになります。
p <- forest(all_results[,c(1:3, 8:9)],
est = all_results$HR,
lower = all_results$CI_Lower,
upper = all_results$CI_Upper,
sizes = all_results$se,
ci_column = 4,
ref_line = 1,
arrow_lab = c("NewDrug Better", "Placebo Better"),
xlim = c(-1, 4),
ticks_at = c(0, 1, 2, 3),
footnote = "フォレストプロットが完成したよ!")
# Print plot
plot(p)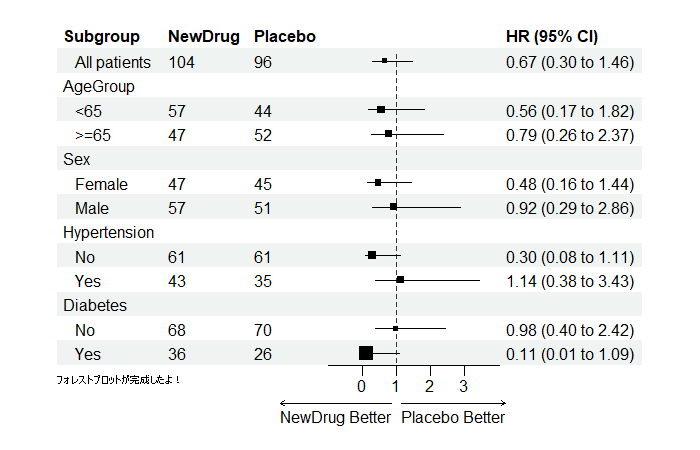 星柴くん
星柴くん四角の大きさが標準誤差を表してるのだ!
黒星柴くん習うより慣れろで、まずはコードをコピペして遊んでみるんやでな
まとめ
R studioを使って無料でサブグループ解析のフォレストプロットを作成する方法についてご説明しました!
皆様のお役に立てれば幸いです!!









コメント