
こんにちは。ほしのはやしです。
臨床研究において、Table 1はほとんどpatient characteristicsで一緒だと思ったことありませんか?
R studioを使う前はJMPを使っていたのですが、『結果をexcelに打ち込んで罫線を引いて…』と多くの時間を費やす必要がありました。
R studioを使えるようになることで、
- 平均と標準偏差の算出
- 性別などカテゴリー変数を%表示に切り替え
- 各項目を統計で検定
- Tableを作成
これがまとめて30分以内にできるようになりました。
このページでは神パッケージ『gtsummary』の使用方法について具体例を用いて紹介していきます!
Rのパッケージのインストール方法は下記ページを参考にしてください!

gtsummary:tbl_summaryの使い方
パッケージの呼び出し
R studioでの一番最初にするべきことは、忘れずにパッケージの呼び出しを行うことです。
library(gtsummary)
library(tidyverse)tidyverseを呼び出すことで、%>%(パイプ演算子)など必要な項目を全て使えるようにします。
gtsummaryは、以下の関数を持っておりTable 1作成にはtbl_summaryを使用します。
- tbl_summary:Table 1の作成
- tbl_regression:回帰分析の表を作成
- tbl_survfit:生存期間などTime to eventの表を作成
基本の構文
データシートの全てを表にすることは滅多にないと思いますので、どの列を解析するのかをselectで示します。
その後tbl_summaryで具体的な解析をしていくことになります。
selectに条件分けで使う列も忘れずにいれましょう!
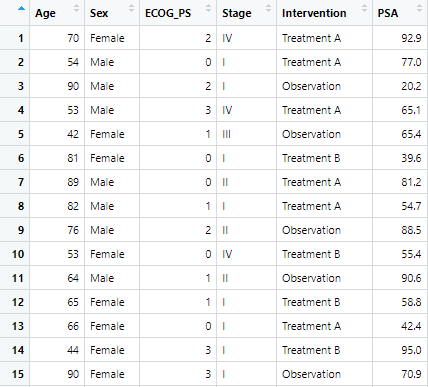
練習用のデータシートの作成
まずは練習用のデータを作成します!
library(tidyverse)
set.seed(123) # 再現性のために乱数のシードを設定
datasheet1 <- tibble(
Age = sample(40:90, 100, replace = TRUE), # 年齢(40〜90歳のランダム値)
Sex = sample(c("Male", "Female"), 100, replace = TRUE), # 性別(男性/女性)
ECOG_PS = sample(0:3, 100, replace = TRUE), # ECOG-PSスコア(0〜3)
Stage = sample(c("I", "II", "III", "IV"), 100, replace = TRUE), # がんのステージ
Intervention = sample(c("Treatment A", "Treatment B", "Observation"), 100, replace = TRUE), # 介入法
PSA = round(runif(100, 0.1, 100), 1) # PSA値(0.1〜100のランダム値)
)テーブル名:datasheet1
gtsummaryを使用したTable 1の作成
今回は、Interventionで群分けして、Age, Sex, ECOG_PS, PSAについて表を作成していきます!
library(gtsummary)
library(tidyverse)
datasheet1 %>%
select(Age, Sex, ECOG_PS, PSA, Intervention) %>% # 解析する列名を選択
tbl_summary(
by = Intervention, # Interventionによる群分けを指示
label = list(
Age ~ "Age, years",
Sex ~ "Sex, n (%)",
ECOG_PS ~ "PS, n (%)",
PSA ~ "PSA, ng/mL"
), # 列名をどのように表記するか指定
digits = list(Age ~ 1, PSA ~ 1), # Age, PSAの少数位を1桁に
statistic = list(all_continuous() ~ "{mean} ± {sd}", all_categorical() ~ "{n} ({p}%)" ), # 統計表記の指定
missing = "ifany", # 変数に欠損値が存在する場合にのみ、欠損値の数を表示
missing_text = "Missing", # 欠損値をどう表記するか指定
) %>%
add_p()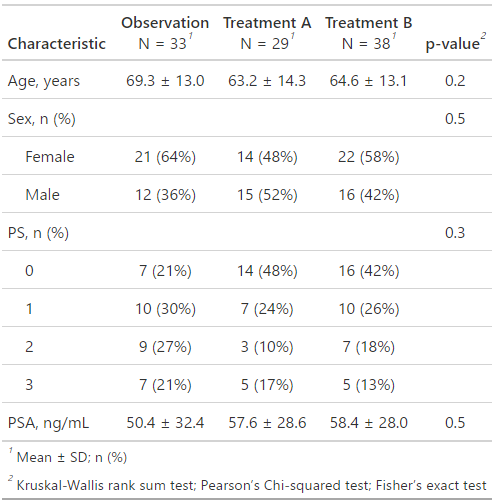
基本の形はこれで完成です!
列名の順番はselect()の順番を変えることで簡単にできます!
もし、特定の項目を中央値(25%値, 75%値)のようにしたい場合は、以下のようにall_continuous()の後に指定します!
datasheet1 %>%
select(Age, Sex, PSA, ECOG_PS, Intervention) %>%
tbl_summary(
by = Intervention,
label = list(
Age ~ "Age, years",
ECOG_PS ~ "PS, n (%)",
PSA ~ "PSA, ng/mL",
Sex ~ "Sex, n (%)"
), # 列名をどう表記するか指定し順番も指定
digits = list(Age ~ 1, PSA ~ 1), # Age, PSAの少数位を1桁に
statistic = list(all_continuous() ~ "{mean} ± {sd}", Age ~ "{median} ({p25}, {p75})", all_categorical() ~ "{n} ({p}%)" ), # 統計表記の指定
missing = "ifany", # 変数に欠損値が存在する場合にのみ、欠損値の数を表示
missing_text = "Missing", # 欠損値をどう表記するか指定
) %>%
add_p()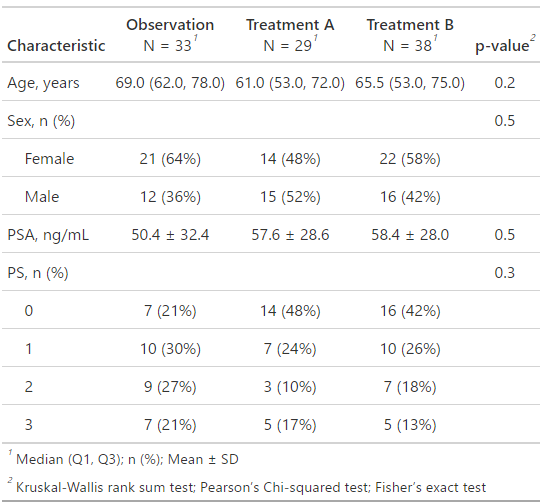
これで簡単に統計も含めてTable1が完成しました!
結果をエクセルに出力する方法
データをエクセルで出力するには、以下のステップが必要です。
あらかじめ、パッケージ『huxtable』をインストールしておいてください。
以下は、出力までの一連のコードになります!
ibrary(gtsummary)
library(tidyverse)
library(huxtable)
res1 <- datasheet1 %>%
select(Age, Sex, PSA, ECOG_PS, Intervention) %>%
tbl_summary(
by = Intervention,
label = list(
Age ~ "Age, years",
ECOG_PS ~ "PS, n (%)",
PSA ~ "PSA, ng/mL",
Sex ~ "Sex, n (%)"
), # 列名をどう表記するか指定し順番も指定
digits = list(Age ~ 1, PSA ~ 1), # Age, PSAの少数位を1桁に
statistic = list(all_continuous() ~ "{mean} ± {sd}", Age ~ "{median} ({p25}, {p75})", all_categorical() ~ "{n} ({p}%)" ), # 統計表記の指定
missing = "ifany", # 変数に欠損値が存在する場合にのみ、欠損値の数を表示
missing_text = "Missing", # 欠損値をどう表記するか指定
) %>%
add_p()
as_hux_xlsx(res1, file = "table1.xlsx") # このRプロジェクトがある同じフォルダにtable.xlsxとして出力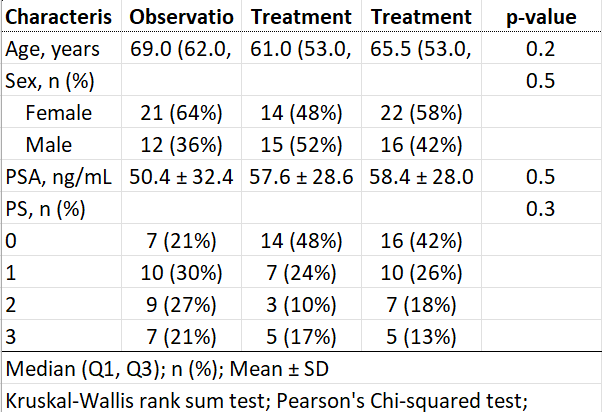
 星柴くん
星柴くんこれであっという間にTable 1が完成したのだ!
 黒星柴くん
黒星柴くんあと数年以内にはエクセルアップロードするだけで全ての表やグラフを作成できる時代が来るだろうけど、こういう知識は今のところは大切なんやで!
gtsummaryをカスタマイズして使用する方法
ここからは、詳しいスクリプトの中身、p値の統計解析の指定などについて解説します!
詳しい解説1:tbl_summaryの中身
ここからはtbl_summaryの中身について解説します!
先程の具体例で使わなかった方法についても説明しますので、興味のある方はご一読ください。
| 指示文 | 意味 | 補足 |
|---|---|---|
| by = 列名 | 列名で場合分けする。 | 並び順を指定したければ、一連のコードの前に、datasheet1$Intervention <- factor(datasheet1$Intervention, levels = c(“Placebo”, “DrugA”))などという形で順番をつける。 |
| label = list(列名~”表示したい名前”, 列名2~”表示したい名前2″,…) | 表の項目の名前を任意に変更する。 | なし |
| statistic = list(all_continuous() ~ “{mean} ({sd})”, all_categorical() ~ “{n} / {N} ({p}%)”) | 連続変数を『mean (sd)』で結果表示する。 カテゴリー変数を『n/全体のN (%)』で結果表示する。 | 指示がない場合、連続変数は『median (IQR)』の表示に、カテゴリー変数は『n (%)』表示になる。 |
| digits = list(列名~小数点以下の数値数, 列名2~小数点以下の数値数, …) もしくは digits = list(all_continuous()~小数点以下の数値数) | 任意の連続変数、もしくは連続変数全体の小数点以下の数値を表示を決める。 | 悩んだらdigits = list(all_continuous() ~ 1)にしておけば、大きな文句は出ない。 |
| type = list(列名1~”continuous”, 列名2~”categorical”) | 列名を”continuous”連続変数、もしくは”categorical”カテゴリー変数にする。 | 列名をc(列名1, 列名2,…)とすることでまとめて変更できます。 基本はなしでやってみて、合わないところのみ修正するのが効率的。 |
| missing = “no” or “ifany” or “always” | 空白の値の個数を”表示しない”or”あれば表示する”or”0でも表示する”。 | 空白のデータがなければ、省略可。 コピペして使うことが多いので、とりあえず”ifany”にしておけばミスが少ない。 |
| missing_txt = “表示したい文字” | 空白の値があった場合のタイトルを決める。 | “Missing”にしておけばミスが少ない。 |
詳しい解説2:p値の設定
tbl_summary(~~~~)のあとは、%>%でつないで、add_p()で追加指示を行います。
デフォルトでは、連続変数はnon-parametric検定、カテゴリー変数はN数に応じてFisherまたはΧ二乗検定(最も少ない項目がN = 5以上)で自動的になります。
詳しく設定したい場合は、以下のような形で個別に修正することも可能です。
add_p(test = list(Age ~ "t.test", Sex ~ "fisher.test"))テストの種類は”t.test”, “wilcox.test”, “fisher.test”, “chisq.test”, “aov”など様々なものが可能です。
詳しい説明3:その他のadd_***()コマンド
add_p()の他にも便利なコマンドがあります。%>%でつないでいくことで、追加情報を表に付け足すことができます。
| コマンド | 意味 |
|---|---|
| add_q() | FDRで調整したp値をq値として表示します。 |
| add_overall() | 全体数での統計結果を表示します。 |
| add_n() | N数を表示します。 |
| add_ci() | 95%CIなどを表示します。 |
| add_stat_label() | 統計表示(例:mean, sdなのか, median (IQR)なのか)を明示します。 |
詳しい内容については、gtsummary制作者のページをご確認ください。
https://www.danieldsjoberg.com/gtsummary/reference/index.html
詳しい説明4:層別化解析
例えば、最初に性別で分けた後で、その中で治療群とプラセボ群を比較したい場合を考えます。
この場合は少し難しく、tbl_strata()を使用します。
datasheet1 %>%
select(Age, Sex, PSA, ECOG_PS, Intervention) %>%
tbl_strata(
strata = Sex,
.tbl_fun = ~ .x %>%
tbl_summary(
by = Intervention,
label = list(
Age ~ "Age, years",
ECOG_PS ~ "PS, n (%)",
PSA ~ "PSA, ng/mL"
), # 列名をどう表記するか指定し順番も指定
digits = list(Age ~ 1, PSA ~ 1), # Age, PSAの少数位を1桁に
statistic = list(
all_continuous() ~ "{mean} ± {sd}",
Age ~ "{median} ({p25}, {p75})",
all_categorical() ~ "{n} ({p}%)"
), # 統計表記の指定
missing = "ifany", # 変数に欠損値が存在する場合にのみ、欠損値の数を表示
missing_text = "Missing" # 欠損値をどう表記するか指定
) %>%
add_p()
)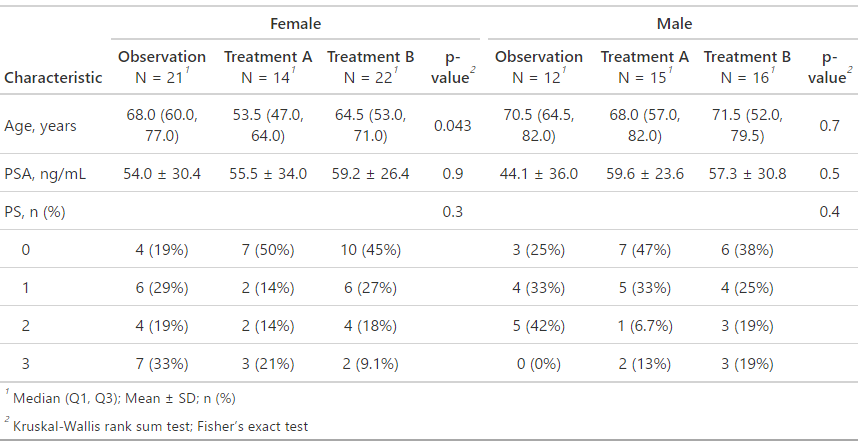
今までやったtbl_summaryの部分をtbl_strataで括弧で囲んだ形になっています。
詳しい解説5:データの並び順を変更したい
例えば、性別をFemale, Maleの順ではなく、Male, Femaleにしたい、ときを考えます。
データに順序付けをする方法がこちらになります。
これを先程の解析の前にデータシートにインプットしておきます。
datasheet1$Sex <- factor(datasheet1$Sex, levels = c("Male", "Female"))まとめ
gt_summaryの具体的な使い方について説明しました。
細かいレイアウトの調整とかもR studioでできるのですが、ある程度ざっくり作ったらエクセルに出力して修正するのがオススメです。
今回のページが少しでもお役に立てれば幸いです。









コメント